Prodects/AI/ML Data Platform in Snowflake
Driving OEM Data Excellence: Solvency's Tailored Solutions for Machine Learning/ AI Data Platforms
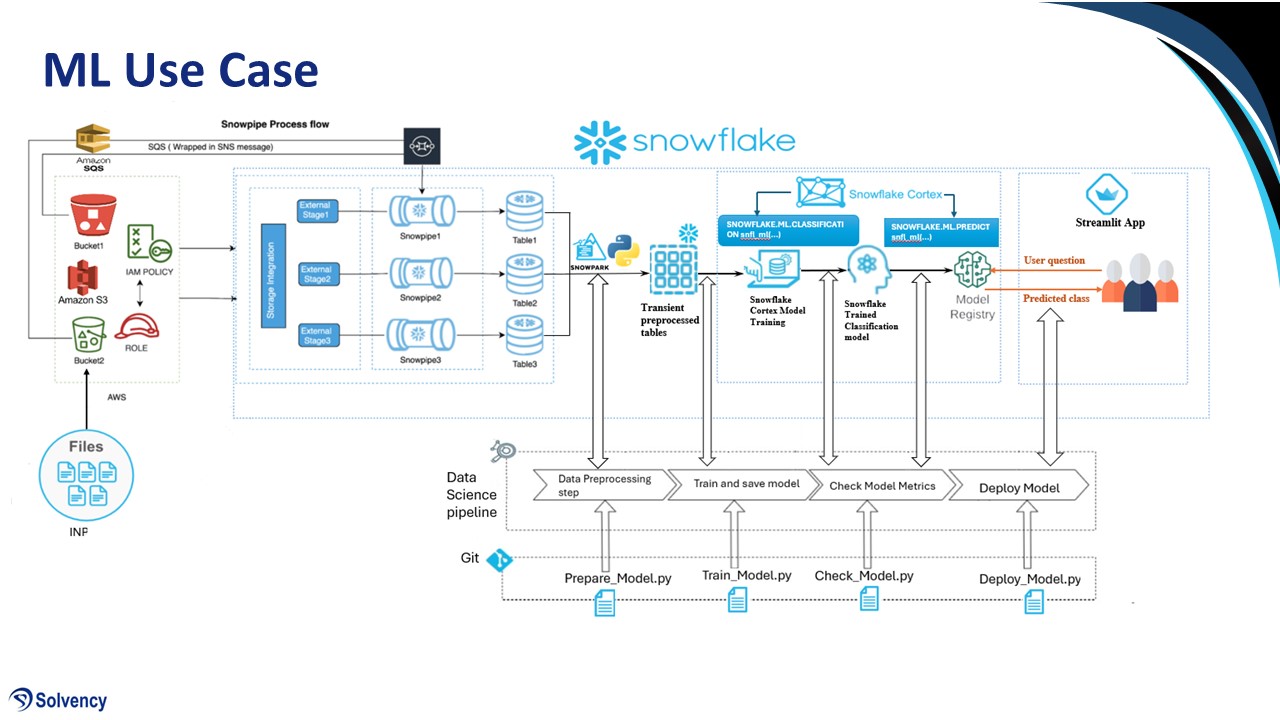
Our data ingestion process leverages a combination of AWS and Snowflake technologies. Data from various OEM sources will be uploaded to Amazon S3 buckets. Upon arrival, Amazon SQS (Simple Queue Service) will act as a message queue, triggering the transfer of files to Snowflake. Within Snowflake, data will be staged using Snowstage and automatically ingested through a data ingestion layer. This layer includes data pipelines (Snowpipes) designed by our solvency team, who are data domain experts.
The solvency team will ensure adherence to data quality metrics throughout the process, from the initial staging phase to the final steps within the data pipeline. This includes implementing data quality checks defined by our solvency experts and upholding data governance and data security practices. Cleansed data will then be stored in Snowflake, readily accessible to solvency data analysts and scientists for advanced business predictions.
Furthermore, professional data pre-processing techniques will be employed throughout the process using Snowpark (Snowflake's PySpark integration). This prepares the data for the application of machine learning algorithms and AI models, ultimately generating the desired predictions.
A visual representation of the complete end-to-end data flow is provided in the following figure.